Listen
Podcast: Play in new window | Download
About



Taylor Murphy is the Head of Product and Data of Meltano, an open source data platform that enables collaboration, efficiency, and visibility. Before joining Meltano, Taylor was the first data hire at GitLab, where he ultimately led the data team as Manager of Data & Analytics. He also holds a Ph.D. in chemical and biomedical engineering from Vanderbilt University.
Recommended Reading
Working Backwards: Insights, Stories, and Secrets from Inside Amazon, by Colin Bryar and Bill Carr.
Inspired: How to Create Tech Products Customers Love, by Marty Cagan.
Amplitude, a blog authored by John Cutler.
Data we collect about our products are really just a summary of the thousands of stories our users would tell us if they could. Part of our job as product managers is gathering and processing these stories, and then converting them into the products and tools that enhance the human experience. Taylor Murphy provides some insight into how product managers can approach data science in this episode.
In this episode of the Product Momentum Podcast, Sean and Paul are joined by Taylor Murphy, Head of Product and Data at Meltano, an open-source data platform whose mission it is to make data integration available to all by turning proprietary ELT solutions into true open-source alternatives.
Part of the PM’s role is to be the conduit through which data are shared, what Taylor refers to as being “the glue and message broker between everyone to make sure folks are aligned.” But data are only one part of the message. And not all data are created equal.
“We’re gathering insights from the market. We’re listening to consultants. And we’re digesting what others are saying about our space,” he adds. “The challenge for PMs is integrating all those data points into “Okay, now we’re going to build this feature; now we’re going to fix this bug.”
Catch the entire pod to hear Taylor’s straightforward approach to data management and data science for product managers –
- Importance of working with anonymized data
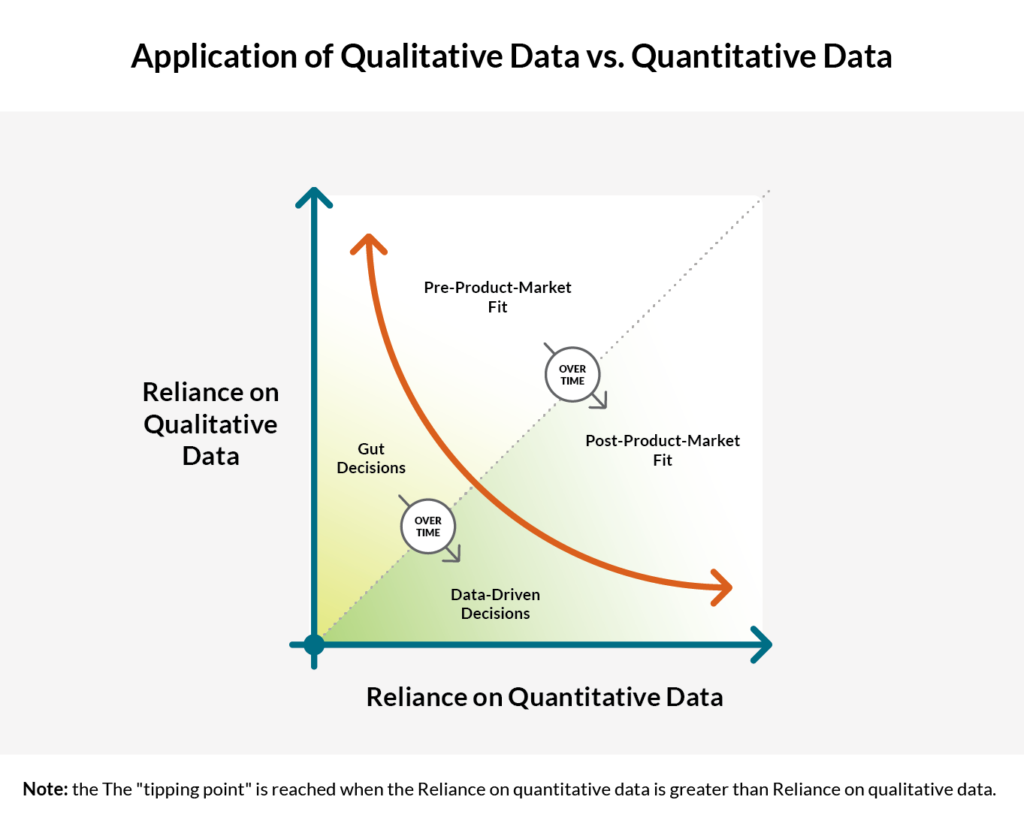
- When, in the product life cycle, to use qualitative vs. quantitative data (see below)
- Applying the golden rule to data sharing
- Risks associated with over-indexing your data
- Role of the scientific method in our decision-making process
- Knowledge of SQL in the PM skill set
Podcast: Play in new window | Download
Paul [00:00:19] Hello and welcome to Product Momentum, where we hope to entertain, educate, and celebrate the amazing product people who are helping to shape our community’s way ahead. My name is Paul Gebel and I’m the Director of Product Innovation at ITX. Along with my co-host, Sean Flaherty, and our amazing production team and occasional guest host, we record and release a conversation with a product thought leader, writer, speaker, or maker who has something to share with the community every two weeks.
Paul [00:00:43] Hey, everyone, and welcome to the show. I’m excited to bring our conversation with Taylor Murphy to you today. We’re going to talk a lot about data and how it’s impacted the product management space lately. There’s been a lot of chatter in a lot of different verticals when it comes to data science. But Taylor has a really pragmatic approach, and I think it was really interesting in our conversation, thinking about it not as an end in and of itself, but as a tool to help you get to the decisions that you need. We’re going to help you figure out how you can apply it to your practice, whether you’re from a development background as a technical product manager, or if you come from a business or a design background, how you can still use it and apply it and help your teams out. So here we go with our conversation with Taylor Murphy.
Paul [00:01:25] Well hello and welcome to the pod. Today we are thrilled to be joined by Taylor Murphy. Taylor is the Head of Product and Data at Meltano, an open source data platform that enables community collaboration, efficiency, and visibility. Before joining Meltano, Taylor was the first data hire at GitLab, where he ultimately led the data team as Manager of Data and Analytics. He also holds a Ph.D. in Chemical and Biomedical Engineering from Vanderbilt. Taylor, so excited to have you on the show. Welcome.
Taylor [00:01:50] Thanks for having me.
Paul [00:01:51] Absolutely. So to jump right in, we’ve all heard horror stories about how data can be a wonderful tool in aggregate, but revealing clues at the individual level can come across as a bit vague or inauthentic at times, and understanding that human connection is really what sets the good data scientists apart from the masters of data. Just to tee us up here, can you share how a good data policy can translate into that genuine human experience?
Taylor [00:02:17] Yeah. When I think about this question, I think about the day-to-day experience of actually analyzing data, and also connecting the data that you individually generate, either with the product that you might manage or just kind of in your regular life. And so think about specific analyzes where you’re going in and trying to understand like user flows in a particular product or even like simple things like billing and expenses within an organization. Those types of data are personal and sensitive. And so we’ve taken like a very specific approach, and I’ll tie this kind of to my work of really only dealing with anonymous data. So like we have product analytics that kind of come back to us and they’re completely anonymous and we do that intentionally because, I personally, and I think we as a company kind of have a strong belief that like specific information about one particular person isn’t particularly useful on its own and also can be seen as like, kind of like potentially kind of creepy.
Taylor [00:03:09] And really it’s kind of the combination of data from the anonymous aggregate stuff that we have, but also data from other sources of like your personal experience of actually using the product or talking to users and getting some of that qualitative data. And so good policy is really not just like what specific events are we firing in this context. It’s about what are like the full scope and set of data that we’re getting as an organization and how are we kind of integrating all of that together? And some of that is, you know, integrating literally like in the data warehouse, you have multiple sources, but also some of it comes in is like the product manager role of, “okay, I’ve talked to this user, I’ve seen this experience, I’ve experienced this myself and also I have some data here that is telling me one thing or another.” So it’s really just about having that kind of holistic view of not being narrowly focused on specific metrics that you’re trying to drive and the data that you’re getting from that.
Paul [00:03:56] Okay. And you just had a recent experience that might shed some light on things. Can you tell us maybe how you took the recent Meltano 2.0 experience and applied some of these insights and maybe ate your own dog food, so to speak?
Taylor [00:04:10] Yeah. So we just had a large 2.0 launch. A lot of the context behind the 2.0 launch was we were getting up in versions. We had like version 1.105. We had some deprecations that we wanted to put in. So I was like, “Look, we need to release a major version, we know there’s some things we want to drop, some major features we’re going to add.” But part of that was improving telemetry across the board. Previously we had gone, I say we, like, this is before I even joined the team. It was using Google Analytics and Google Analytics was like a good first iteration. But for these back-end events, it just wasn’t giving us kind of the information that we needed.
Taylor [00:04:42] And so the part of the goal with 2.0, too, was to improve the telemetry so that we could understand basic things like of the users that are sending us data, because we do make it easy to opt out, of the ones that are sending us data, like, do we even know what version of Meltano they’re on? Because that wasn’t something that we’d had previously, you know, information about kind of the system that it’s working on.
Taylor [00:04:59] But one of the other big things that we were thinking about is, it’s not just, “okay, what are we going to benefit from the data that we’re capturing? How can we take that data and actually give it back to the community?” So we have Meltano hub, which is a centralized place to find all of the plug-ins that are installable with Meltano. And on there we are listing information about how often it’s installed within Meltano and then the number of projects that we’re actually seeing that on. And so our expectation by gathering richer information about basically percentage of like successes with this particular plug-in, percentage of failures, we want to turn that data back around and feed it into Meltano hub and give it back to the community.
Taylor [00:05:35] That’s one of the challenges we’re trying to solve is lack of transparency, or rather, difficulty of understanding, like the quality of a particular plug-in. So the telemetry enhancements are about getting a bit more information, still keeping it anonymous, still making it easy to opt out, but hopefully showing the value to users of like, “hey, if you’re going to give us your data, we’re going to treat it with respect and we’re going to give a lot of it back to you in kind of this aggregated form.” So it was a fun experience, a lot of back and forth to understand, you know, what we can get, what we don’t want to touch, what’s risky or how are we going to hash things? And all of it was done kind of out in the open in our public issues to really keep the community involved and informed.
Paul [00:06:10] Love it.
Sean [00:06:11] So you said you should only be dealing with anonymous data, and you mentioned this is about needing to have a holistic view of the data. What about quantitative versus qualitative, like having this broad base of data but actually being able to make a decision at the ground level? We know the context is really important. Like, what are your thoughts on how deep do you have to go, like looking at individual anomalies in the data versus just paying attention to holistic stuff?
Taylor [00:06:36] Yeah, my sense on that is it definitely depends on your scale as an organization. So Meltano right now is essentially pre-product-market fit with our new and expanded vision. We had focused previously on just ELT and we had some good success with that, but we kind of have refocused and re-expanded our vision. So I say that because if you have a large established product, I think the quantitative can make more sense. Like you would have enough sample data to understand statistically significant changes and effects based on running some small tests.
Taylor [00:07:11] At the scale that we’re at, the quantitative only gets you so far either because you have just not enough data or it’s just not meaningful for what you’re trying to do. Because pre-product-market fit, I think you’re trying to swing for the fences, as it were, make some big bets, and see what’s going to start sticking with the market. So the qualitative comes in there where I’m having conversations with users and understanding, “Oh, this is nice and I’m using this feature,” so that shows up in the data, “but it would be great if it did this,” or, “I would love to try this and here’s how I kind of shimmed it together and for whatever reason, that doesn’t show up in the data,” and I wouldn’t have understood that otherwise.
Taylor [00:07:47] So it’s about having those conversations. It’s about running through the product yourself, like, we learn more on a regular basis just by dog-fooding the products, spinning up a new project, going through our onboarding workflow and saying, “Oh, this is an issue, this shouldn’t be like this.” Little things like for certain CI commands, the startup time feels way too long and that wasn’t coming through via the data. And that only came through through that qualitative experience. So my, well, I don’t even wanna say my guess. Like at GitLab, like, we have enough data where you can run some experiments and see, you know, statistically significant changes in performance and metrics that we care about with small tweaks. We’re just not going to have that at the startup scale. So it’s a balance and I think it’s shifting. And as you kind of grow and mature, you can lean more on the quantitative. But for the early stage, when you’re trying to deliver that customer joy, the qualitative is going to be the big driver.
Sean [00:08:39] That’s an interesting distinction, like, there’s a tipping point where, you know, the quantitative becomes more important than the qualitative when you have enough data, but you to get there first, right?
Taylor [00:08:48] Right. I do think some of it’s like tied to the business and what the business is measuring. For a company like Meltano, which is pre-revenue, that in and of itself is like a huge metric. Like the, you know, income right now is zero. But we have other metrics that we care about, growing the open source community. When you have a larger organization and you’ve got a sales team and there are clear metrics that drive things, you need to have the metrics start to flow all the way down. At least that’s what I’ve seen in my experience.
Sean [00:09:12] Yeah. There’s another, like, trap that always concerned me with qualitative data in that there’s so many cognitive biases that people have that when you read through qualitative data to try to make decisions, there’s no way that those things aren’t at play and you’re going to make more mistakes. You’re kind of sifting through that stuff.
Taylor [00:09:29] Yeah. One thought that came up while you were sharing that is, the qualitative data necessitates then much tighter feedback loops. When you have more quantitative data, you have more data coming in, you can take steps or make decisions maybe that are a little bit more riskier because you had the data to back it up. When you’re getting that qualitative feedback, I think you should tighten the feedback loops as much as possible and make the iterations as small as possible so that you’re not flying completely blind.
Taylor [00:09:59] We at Meltano have a value. Previously it was iteration and now we kind of folded it into this, this progress over perfection, with the idea that the smaller the iteration, the quicker that we can get it out, we’ll get more feedback and help us course correct in whatever mechanism we have available to us. We can do that faster and hopefully get on a better path much sooner. So when we put a feature out, generally we’re releasing basically every week. We have community calls on a regular basis. We’re getting that data back from our users about whether this is working, what’s not working. If we kind of sat behind our desks for two months and then released something, that’s a long time to be flying blind. So I think the qualitative hopefully will encourage folks to do smaller iterations and release them more quickly.
Sean [00:10:40] I think that’s an important insight. Something you said answering the second question, too, I want to pull on that thread just a tiny bit.
Taylor [00:10:46] Mm hmm.
Sean [00:10:46] You were talking about telemetry data and trying to get tighter and more valuable telemetry data. And then you mentioned giving data back to the consumers. And I’ve always found that to be a fascinating thing too, in software products. You know, when you’re collecting a bunch of information for people, this is somewhat anecdotal, I don’t have any data to support this. But when you give a little bit of that back to the customer and you show, “Hey, people like you answered this,” or, “here’s some value from the data that you just gave us that we know is going to help us build a better product for you, here’s a little give back.” How have you deployed that? Like, what have you found works well in terms of how to think about giving a little bit of information or consolidated data back to the consumers?
Taylor [00:11:25] Yeah. I think we’re going to be experimenting with that. The first pass was us taking a look at the data that we had and saying, “Okay, we know how many projects these different plug-ins are being run and we know the number of executions, whether those were successful or not.” That wasn’t something we were aware of up until kind of this new launch. But part of it comes from, I think, the philosophy of like just the golden rule. If you’re using a product, what would you love as a consumer? What would you want to be the experience? And if you’re generating data and in aggregate that information is useful to you individually, that’d be great to have back. A lot of companies, I think, will see that and say, “Oh, that’s something that we could sell back to the user potentially.” And I think there are companies that do that.
Taylor [00:12:08] Us being an open-source project and trying to kind of elevate the whole space, that thought has never really crossed our mind and we just, if we’re getting the data, if we just kind of want to put it back, because I think it’s kind of a virtuous cycle where folks will understand the value of the data that they’re generating and the value that it creates when it’s shared back with the rest of the community. And we kind of want to be a vehicle to do that.
Taylor [00:12:29] So I think the information that we’re going to get, I’m very curious to see, we just started having some events flowing through. The data engineer that reports to me and starting to clean it and transform it. I think the first thing we’re going to do is share back, “Hey, in the projects that are running this particular plug-in, we see a 98% success rate and in the past day it’s dropped to 60%.” And that can actually be a signal for us to say, there’s a problem in this open source project that’s upstream, we can go file an issue or somebody in the community can be proactive about it. For an open-source project like ours that also relies on a bunch of other open-source projects, being that kind of broker or source of information can help make the entire community experience better, not just for Meltano users, but for users of all these other open-source projects.
Paul [00:13:15] Love it. It’s a very human approach to data. It’s surprisingly human. And I think one of the things that’s resonating and that came through in the conversation we had prior to hitting record here today is just how there is a risk of over-indexing on what the data is telling you and then essentially over-relying and trumping your intuition and not really talking to the humans that are behind the platform who are using the thing, that are solving the problems in their lives. So can you unpack some of the lessons that you’ve learned along the way that kind of prompted that kind of thinking that, you know, it’s unlikely that all the data you’re gathering from the product is going to tell you what’s not in the product. It can tell you a lot about what’s on the platform, about the component or the usage. But the one thing the data is not going to tell you is what’s missing because it can’t measure what’s not there. What are some of the experiences that you’ve had where talking to people has prompted things that are sort of outside of the data conversation but inform it?
Taylor [00:14:10] Yeah. One thing that as you were talking, I was thinking about is why there is this overreliance on the data. And so I’m kind of taking your question in a completely different direction. So I’ll circle back to the main point. But what I was thinking about is I think there are interesting incentives in different companies around product management and the data that’s being generated. And if a company doesn’t have an environment or culture that is safe, frankly, for lack of a better word, for people to try things, to make mistakes, and to understand the effects that the decisions that they’re having in a way that doesn’t come back on them. I think people tend to over-rely on the data because, “if the data say this or our data analysts or our data scientists say this, then I’m going to do what they say.” And that’s like a very safe decision. And, you know, “my promotion’s not at risk or,” you know, whatever. It’s not at risk. It seems good.
Taylor [00:15:04] And that’s short-term thinking and they’re probably not wrong for a period of six months to a year, but it can be harmful long term. And so for me, it’s like, are you in an environment that supports that long-term thinking, that integration of the quantitative and qualitative in a way that it’s okay to make safe bets around what the product is doing, what kind of customer experiences you’re trying to go for. Because fundamentally, I think there are ways to incrementally improve a product with the data, and the data can show you how to do that. No amount of data is going to tell you, like, “we need to fundamentally shift our business or we need to completely re-architect how this experience is for our customer.” Maybe you can get some of that, but it’s kind of a narrow, like, data will tell you how to optimize the processes. It won’t tell you how to go from a local optimum to kind of a global optimum.
Taylor [00:15:51] So coming back to your specific question around, like, product experiences that have changed out of conversations. I distinctly remember having one conversation with the user where he was basically using Meltano to manage a completely different project that is technically closed source, but they have like their own command line. And he was just raving about how like, “Oh, I love using the command line for this other tool, but I’m running it via Meltano because I get all of these other benefits.” And we kind of had expected that, but to actually see it in the wild was really cool and it encouraged us to really start pushing more on the Meltano Hub experience to make it the source of truth for what plugins are installable and to start trying to get more people to contribute to Meltano to say, “look at all these tools that you can use with Meltano and here’s the benefits that you get from it.” And we want to make it so that people want to contribute to Meltano Hub to make it better for everyone. Yeah, I hope that answers your question. That was kind of long-winded.
Paul [00:16:44] It does, yeah. No, I think that those kind of real-life examples are the only ways that you can understand these things. And prioritization can only take place once you understand where people’s pain points and delighter points are. Somebody really enjoys that command line and they’re utilizing it in an unconventional way, but gives you insight into the product that you never would have had without having that conversation. So I think that that kind of data mindset is counter to some of the more tactical firefighting. You know, when does something break or when do people abandon? Or some of the data silver bullets that people keep looking for. Even after all of these years of insight in the community, it really does come back to the basics and having those good human insights to what people are trying to get done in trying to help that problem get solved, I think is a really telling attribute of how you’ve built up this data mindset in your practice.
Taylor [00:17:36] Yeah. For me, some of it comes back to grad school, honestly for me, because, you know, in grad school a lot of it is just applying the scientific method constantly and repeatedly for very particular questions. And for me, before even stepping into a product management role, I was strongly suspicious of product management as an application of essentially the scientific method, but for like customer experiences. And now having lived in this role for a while, like that’s not an unfair description of it. And that’s basically what I feel like I’m constantly doing is saying, “okay, I think this feature or this enhancement will improve the product or the experience in this way.” And part of, you know, specing out an issue is talking with the engineers, talking with users to say, is this, you know, “something like this would make sense?” And then it gets built and then you get the data back and then you kind of had that whole feedback cycle. And it’s all about figuring out, you know, the truth or the discovered reality of what’s going to be the best product for your company and your customers. And so it’s been fun for me to feel more comfortable drawing on that kind of scientific background and being able to apply it in a more product-focused sense and relying kind of on all those data skills as well.
Sean [00:18:41] Yeah, you have a Ph.D. in chemical engineering.
Taylor [00:18:45] Yeah.
Sean [00:18:46] And it’s funny to me because I’ve worked with lots of Ph.D.s over the years, and it’s amazing to me how much applicability there is in that world today with data. I mean, it’s you almost have to be a programmer today and really understand these statistical tools in just about any Ph.D. program, right?
Taylor [00:19:05] Yeah. I think for me there was an element of programming. The work that I did, like looking back on it now, you know, I’m super grateful for the experience. In the middle of it was a slog and I knew I didn’t want to be in academia, although I’m glad I stuck with it. The work that I was doing was very multidisciplinary, and at a very high level, it was very focused on essentially systems thinking. So like chemical engineering is all about chemical systems and reactions and flows and all this fun stuff. And what we did is apply that to the study of cancer metabolism. And so we did these experiments in the lab, and then we had these computer simulations and we tried to make them match up with each other. So that’s kind of where, like, all my data chops had started.
Taylor [00:19:43] Like, taking that lens on product and on community. It’s, it’s a lot of systems. There’s a lot of systems going on. And the question is, “Okay, I have a model of how the system works in my head, and I have this data that I’m trying to kind of match it.” And you’re always doing this calibration of, “is the model that I have in my head accurately represented in the software that we’re using, in the issue tracking system? And then how does that match the model of these systems in other people’s heads?” And so part of my job is, I feel as a product manager is talking to, okay, the CEO thinks we’re doing this, the Head of Engineering thinks we’re doing this, Head of Marketing thinks we’re doing this, and I’m acting as kind of the glue and the message broker between everyone to make sure folks are aligned. And here’s the source of truth on the issue. And it’s this big system that we’re trying to corral. And so the data, again, is like one part of that that comes in from the users in the telemetry. But there’s all this other data that, “here’s what the market is saying, here’s what Gartner says about our space.” And you have to kind of integrate that all into, “Okay, now we’re going to build this feature, now we’re going to fix this bug.”
Sean [00:20:43] Yeah. I think the lesson there for me is the scientific method is an amazing tool that we’ve been driving the world forward with and I don’t think we apply it enough in this office. You know, coming from a Ph.D. from chemical engineering and having such a successful career in software, there’s a lesson to be learned there. So thanks for sharing that.
Taylor [00:21:01] Yeah.
Paul [00:21:02] Yeah, just getting down to brass tacks, jumping off of the scientific method idea, you have to start from facts. You have to start from what you know. And just taking this somewhat heady conversation so far and turning it into something practical for a product manager mid-career or looking to specialize into a data superpower in their career, how can they look for opportunities to take things they know and things they assume and come up with a hypothesis that’s testable? Somebody who’s maybe not as well-versed in the world of data science or analytics, how can somebody get started and what tools might you suggest they look at to get a step down this journey?
Taylor [00:21:41] Yeah. I think there’s a bunch of different directions you can take that first and this highly depends, obviously, on your context, whether you’re new in a role and what the culture is like. Understanding first, basically take an audit of, what’s the data that we have coming in, what are all of our sensing mechanisms around our users, around the product? Is this even a product that I as a individual can use? I have a personal bias towards companies and products that I actually get to use myself and can really understand the workflows. So working at GitLab was great because we use GitLab constantly and every day. Same thing for Meltano, so I don’t use it quite as much as I do GitLab. But as a practicing or former data engineer, I know what that experience is like. And so that’s like a personal bias. And so this advice may not work if you’re building a product for a completely different customer persona. So I see some of myself in our customers.
Taylor [00:22:31] But specific tools, like honestly, learning any amount of SQL for data analysis is such a game changer. The difference in the product managers that I worked with at GitLab were those who were even somewhat comfortable with SQL, whether you can filter out a couple of columns, and we’re not talking like you need to do complicated window functions with predicates or whatever, just being able to say, “point me to some data,” and knowing how to manipulate it a little bit or even getting it out in such a way that you can put it into Excel. That is a very concrete skill that is going to unlock some doors for you and can also bridge the gap between your either your data teams or the folks who do kind of have the keys to the actual data. You can say, “Hey, I was playing with this and I had a question, you know, here’s the queries that I run, and I have a specific question about how to improve this.”.
Taylor [00:23:16] Aside from like other specific tools, I don’t really have recommendations on, you know, issue trackers or product management tools. We went through a huge transition as part of the run-up to this 2.0 release, we moved all of our projects from GitLab to GitHub, and that has completely blown up all of my workflows. I had a good sense of where we were going, what the roadmap looked like, and now everything is migrated over. We moved the issues, we moved the labels, but it’s a mess. And I’m still in the progress of kind of picking up all the pieces. But on the bright side, it’s giving me the opportunity to fundamentally rethink, what are the goals, what am I trying to accomplish? What is the context that I’m trying to share with the rest of the team? What’s the proper level of abstraction? So I’m trying to stick with 100% GitHub because they have some project features and labels and all that fun stuff. You can make it work with anything. I really don’t think it’s the tool. I personally really think it’s the processes and the culture that you have in place around these things. You can make it work with a lot of things. I will say one thing, you just have to have a source of truth at some point, whether it’s a Confluent doc or a Google doc or a GitHub issue, there needs to be a shared understanding of, “we agree that this is the recorded source of truth for this, and we’re going to update this in a single place.” Because if you have people jumping around different things and having these shared misunderstandings, then it’s just not going to work.
Paul [00:24:28] I don’t know if that’s a deceptively simple or deceptively complex ad.
Taylor [00:24:32] Easy to say, hard to do.
Paul [00:24:33] Exactly. That’s the better way to put it, for sure. Thanks for that. There were some great nuggets in there.
Sean [00:24:38] Yeah, we always talk about having to have single sources of truth for things, and then, you know, data gets moved all over the place and we end up creating more messes. So I’ve got a couple of key takeaways here for you that I’d like to just bounce off here that I collected from our conversation. First one is that we should be dealing with anonymized data, and we need to have a holistic view of that data. But there’s a tipping point that occurs in that product lifecycle. Qualitative information is more important in the beginning when you’re pre-product-market fit and then afterwards, when you start to collect a lot of data, it becomes like this a tipping point where the quantitative stuff becomes more important.
Sean [00:25:14] The second one is that qualitative data requires tighter feedback loops. That should be a rule. I like that. Number three is that it’s valuable to think through how you can give data back to your consumers. And obviously, you’re in the open source space, so I think that place is generally expecting of things like that. But I think it’s an important thing for product leaders to be thinking about all the time. Like if you’re going to be collecting data, how much of it could you give back in valuable ways to your consumers? Because that’s a way to get them more engaged, more bought into the product, you know, build a better relationship with your consumer. So that’s number three.
Sean [00:25:51] Number four, be careful not to overindex on those big data insights that we get because data doesn’t tell you what’s missing. You still need to go out and talk to the people, to the humans that are using the products and that are making these decisions because you have to have this mix of qualitative, quantitative. The fifth lesson I captured is that the scientific method, we often like let it get away from us and we just like throw things at the wall like spaghetti, right? I think it’s important for us as product leaders to always step back and think about how could we make sure we’re rigorously applying the scientific method to our decisions, and to use Paul’s phrase, let’s always make sure we’re starting from facts. The more facts we have, the more facts that we’re starting from, the better the results are going to be for everyone in our product ecosystem.
Sean [00:26:31] And the last is that there’s, and I’ve heard this one in a few different circles, and I do agree, product managers that are armed with data or the ability to go get their own information but know some basic SQL, or at least know how to tap into a database, maybe use some database tools, are more powerful. I think that that’s an important skill for product leaders to consider going and getting. What do you think? Is that a good set of takeaways?
Taylor [00:26:53] Yeah. I’m shocked that we covered that much in this conversation, but I think those are excellent takeaways. And yeah, that could be a whole blog post, frankly.
Sean [00:27:02] Couple of quick questions and then we’ll wrap up. One is, how do you define innovation?
Taylor [00:27:08] How do I define innovation?
Sean [00:27:10] Yeah.
Taylor [00:27:11] I don’t know if I’ve ever actually thought about this question that deeply. I think, so, for me, innovation kind of comes down to doing something in very unexpected ways or doing it in a way that is easier than you could have imagined. I think there are products that we’ve used where it feels innovative, and usually that’s because either whatever you’re doing is completely new and so maybe a specific example would be like any of the AR-related features, the augmented reality features of like your iPhone. That feels really innovative because it’s not something I’m doing in my normal experience. Or the other side of that is something that I do a lot, but it’s now just suddenly easier. And I’ll lean on Apple again for this experience where I can copy something on my computer and paste it on my phone and vice versa. And that’s something that, it’s just, it’s really cool and it feels really innovative.
Paul [00:28:00] Last question that we have for you, I think is one we’ve kind of danced around a bit that you’ve talked about places you’ve been inspired by, but can you share some books, blog posts, or other sources of inspiration that you’ve gone to that you think a product manager might benefit from?
Taylor [00:28:14] Yeah. So actually it’s funny you say that. I recently read Working Backwards, which is the inside stories and secrets from inside of Amazon, which I really liked. And again, that kind of like ties into the idea of the scientific process, where are you trying to aim for, what’s your hypothesis, what kind of experiences do you want? And then the other book I really like, I think it’s Inspired by Marty Cagan, and I think everybody would kind of recommend that one, really good book I’ve read a couple of times, and I kind of walk away with new insights from that book quite a bit. As far as blogs or writers, I think his name is John Cutler from, I think it’s Amplitude.
Paul [00:28:47] Yep.
Taylor [00:28:49] So he’s great. And then Lenny’s newsletter. I can’t even remember the guy’s name, but I’ve read several blog posts of his.
Paul [00:28:57] Cool. Great recommendations for sure. And Taylor, thank you so much for taking the time today. It’s been a pleasure getting to know you, hearing your insights and learning from you. Thanks again.
Taylor [00:29:06] Really appreciate you having me, guys. Thanks.
Paul [00:29:08] Absolutely, cheers.
Paul [00:29:12] Well, that’s it for today. In line with our goals of transparency and listening, we really want to hear from you. Sean and I are committed to reading every piece of feedback that we get. So please leave a comment or a rating wherever you’re listening to this podcast. Not only does it help us continue to improve, but it also helps the show climb up the rankings so that we can help other listeners move, touch, and inspire the world, just like you’re doing. Thanks, everyone. We’ll see you next episode.